The War Machine
In this post, I'm going to talk about my experience reading Seta in Italian. I won't be talking much about the story of the book and whether I liked it or not in the end. Instead of that, this text will be quite data-centric. It's about hard facts and reliable numbers, so at least I know Linda will read it. And hopefully more people as well. To all of you: welcome!
https://www.youtube.com/watch?v=sm8TtOnTLdg
Okay, let's get started. Incidentally, this is the first time that I'm writing this post using the Journaly text editor. Until now, I wrote all of them using a plain text editor (I love Geany) and pasted the result immediately before publishing it. But never mind.
So, the book Seta. If you watched the last livestream (and paid attention) of the amazing Multilanguage Book Club, you'll already know I've read the book during my holidays, in two days. It's been 22 months since I was last in Catalonia (if you're going to call that Spain, please leave this text 🤭), so it was definitely a good thing to reset that counter back to zero. Again, never mind.
So, the book Seta. I've read the whole book (okay, it's not that long) using a very simple book reader programmed by yours truly. Instead of just describing the poor thing, let me show you how that looks like. Let's see if I find it... Ah, here it is: https://asciinema.org/a/9bITXnQ4vF9GM5lk5E1kge8lr. Have fun.
Now that you're back from watching that tiny "video" recording, you have a better idea of how my reading experience looked like (and also about my horrible taste of a color scheme for highlighting words on the screen). The essence of the computer program is: It highlights words according to their knowledge. If you know about LingQ or similar software, you'll immediately understand what that means. As I didn't c̶a̶r̶e̶ know about the different already existing software products, I just wrote my own little baby, tailored to my specific needs, wishes and bad ideas. So I'm using that for reading e-books, which I convert first (using Calibre) from the original format (.epub, say) to a plain text document, which is what the program uses.
So, the book Seta. The repetition of sentences reminds me of something I've read lately...
Before actually reading Seta, I went through parts of the vocabulary (as you can see here: https://asciinema.org/a/23zWlUx1FkRSABXdoGG7JBVAY). There, I basically rushed through the most frequent (and thus important) words in the story and marked them according to my estimated state of knowledge. Since I officially don't really speak Italian, there are a lot of unknown words (the red ones). Part of the fun is exactly this: Reading in a foreign language that feels quite familiar. As I wrote somewhere else (https://journaly.com/post/11675), I read the previous book for the second round of the Book Club (it was just wonderful to be able to choose something of your own liking!) also in Italian. I liked the experience so much that I'm repeating it this time.
After having entered a substantial amount of new words and having read the book, I plan to train (and hopefully improve) my vocabulary of the book during the remaining time of the Book Club. The reviewing process looks like this: https://asciinema.org/a/DZ09Gi96NyyvUb35811lN8VxU (the screen size is smaller because I used my smartphone for that).
Okay, I promised there'd be some numbers in this text, so let's get started. I hope you're ready.
https://www.youtube.com/watch?v=TtEvE1-cD1E (If you aren't an adult, please don't watch that)
As I said, I don't really speak Italian. By that, I mean that... well, that I don't speak it. More concretely, I didn't fully start to consciously and actively learn the language (i.e. grammar) yet. All I did so far is reading books and training vocabulary. Or rather than "training" it, it's mostly been just entering it into the mentioned computer program for the first time.
Until now, I've entered exactly 12,300 words. Read that again, or to get a feeling for it, watch this: https://asciinema.org/a/A7GX4GIxTJV6NiER8q2yBIc7M. To be precise, my complete current vocabulary knowledge of Italian can be found here: https://zerobin.net/?9e264f2132dc6f4f#go6Pa9X3zeqCspKaCqXSoXZqJD5csVuvz6U9+xTyg1E= (the password is "italian", very original, I know). The nitty-gritty details of this huge text file are, let's be honest, boring, so I've prepared a more digestible form of presentation: a picture. There you go: https://i.imgur.com/YlHj9bE.png.
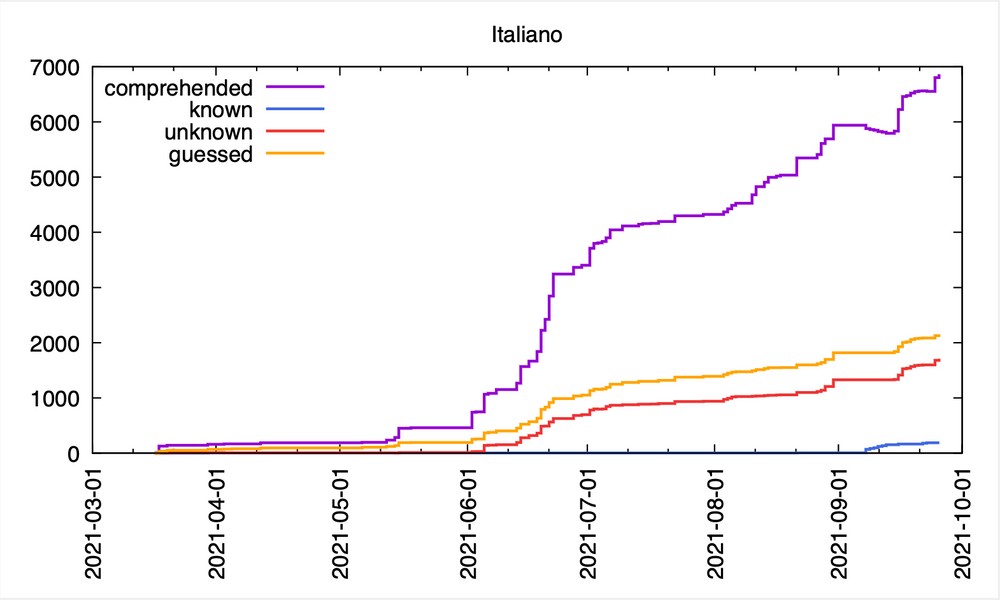
The graph https://i.imgur.com/YlHj9bE.png shows the evolution of my Italian vocabulary since I started my romantic journey with that romance language some months ago. As you can see, I started taking my experiment of "reading without knowing" more seriously in June. The majority of words have the state "comprehended", which means exactly this. They are part of my passive knowledge. My (estimated) active knowledge is still quite poor (as the blue line shows) and I plan to improve that in the upcoming weeks. This process of interiorizing words is showed in the purple graph by a decrease, as you can see in the picture towards the end of the timeline (in September). This is just a cryptic way of saying that I reviewed comprehended words and rated some of them as known, thereby activating part of my passive knowledge.
The previous data is of a global nature, it's not context-specific. It tells you all sorts of things about my knowledge of Italian vocabulary. In other words: Until now, there's no trace of the concrete book I've read, that is, Seta.
So, the book Seta. In order to visualize my knowledge of the vocabulary in the book Seta, I came up with the following form of graphical representation: https://i.imgur.com/xia81F4.png.
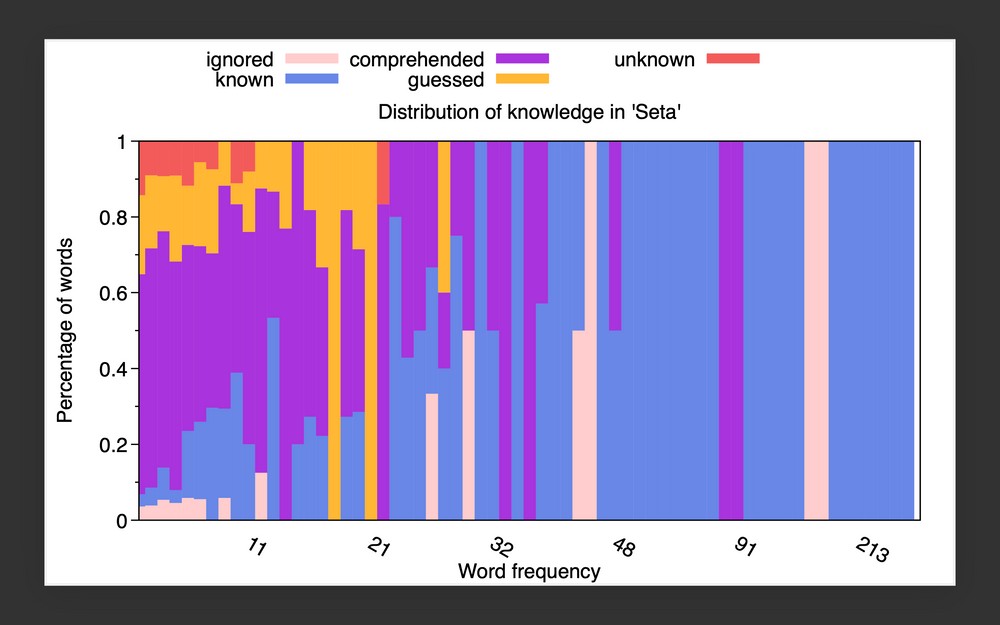
The horizontal axis shows the frequency of words in the book (pay attention that it's not linear, because not all word frequencies have occurrences: for example, there's no word that appears exactly 50 times, for example). The vertical axis shows the number of words in each category (these are: IGNORED, UNKNOWN, GUESSED, COMPREHENDED, KNOWN) divided by the total number of words at that frequency, or in other words, the percentage of unknown words, etc., at every frequency.
The previous picture is the main result of my data analysis and its graphical representation. In case you're curious about the raw data (i.e. the vocabulary of the book), here it is: https://pastebin.com/Pc93JkpF. These are all the (unique) words in Seta. A similar list, containing the words in decreasing frequency, is here: https://pastebin.com/hNwtBepk. This last word list is what my program uses for training vocabulary.
I hope this text has been informative and not too dull to read. I'm curious about your opinion and value every (constructive) feedback about the text, data, graphics or program. Furthermore, raccoon GIFs are always welcome. So here is one: https://media.giphy.com/media/RxVNyswc0Igj6/giphy-downsized-large.gif.

Molto bene!
I feel like I just edited War and Peace. I need a nap 😅
And I tried to make it not too boring/dull to read... 😬
Thank you for all your corrections and comments nonetheless! (Before CocoPop: 44 comments. After CocoPop: 101 comments 😆).
I just meant that it was looooong 😉 But it was certainly more readable than the mathematical posts, so this was definitely a step in the right direction 👍🏻
Wow, it's fascinating to see how you approach language learning! I don't have a math-oriented brain so would never do something like this, but it's great that it works for you. Do you think that starting with reading has been an effective way for you to learn Italian? Do you know how the words are supposed to be pronounced? When reading, I always need to hear the words pronounced in my head, even if I don't actually say them out loud. This is my biggest problem with reading in Chinese. Many times I can guess the meaning of an unknown character I come across, but without knowing how to pronounce it I feel stuck.
Thank you, Wendy, for reading my text and commenting! Is your "something like this" referring to "writing a computer program to learn vocabulary" or rather using it (or both)? About the math-oriented brain: In my case, I don't think I have/use a math-brain while learning a language or even speaking it (but certainly when writing a program for it or analyzing the data it produces and making such graphs). All of this I just do in order to evaluate whether what I'm doing makes sense (or just for fun). The most fun I have by using the program. I actually think I'm as well quite much of an auditory type/learner. At least I rather think in (spoken) words than in pictures, and I definitely enjoy things like podcasts and audiobooks a lot. For example, I "accidentally" learned a lot of Dutch words (long time ago) just by listening to (all of) the Harry Potter audiobooks, and I also have to pronounce the words in my head while reading and especially trying to learn new words. If I don't know how it's pronounced, then I don't have the feeling I understand it, and I certainly won't recall it later in the future. Thankfully Italian has a really transparent and straightforward pronunciation of the written words, so I have a hopefully decent idea of how words have to be pronounced. It's quite a coincidence you mention the "auditory" aspect here, because I thought yesterday (again) about extending my program with a new feature: Speaking the word in, so that the user (okay, in that case it's just me :D) can exercise pronunciation and (at a later point in time) hear the sound of it and match it to the written word somehow. I'm thinking about some sort of clozure test, but with spoken language instead of a sentence on the screen with a ____ in it. Another idea is a simple association/matching game (like writing the word you hear, or something like that). But that's just an idea. What do you think? What sort of computer program could help you to learn and remember vocabulary?
Ah, I still have to answer your question "Do you think that starting with reading has been an effective way for you to learn Italian?". Let's see: I don't actually think I learned Italian-the-language yet, but only a handful of words beyond "pizza" and "pasta". But yes, I do think that it helps. Or at least I really hope it does, after that amount of work! Furthermore, reading is not the only activity that I do in Italian, I also watch https://www.raiplay.it/programmi/ilprovinciale from time to time. It's not just enjoyable but also amazing how much spoken Italian one understands only by speaking another Romance language up to a certain level. I guess that what makes it enjoyable is that it's a sort of relaxed guessing game. As a next step, I found nice, freely available and qualitative audiobooks on Youtube for the books I'm considering reading next, like https://www.youtube.com/watch?v=AIM93r4DE2w or https://www.youtube.com/watch?v=4lquaE_nlAo, which I could combine with reading.
@edufuga I guess I meant I would never write a computer program to learn languages. I do use LingQ sometimes, and I also use various other apps, but what I enjoy most, once I reach a certain level, is just reading or watching videos in their original format, as they were meant to be consumed by native speakers. I use LingQ only for the languages where I still need the extra help. It's true that pronunciation in Italian is very straightforward, so I can see how your current method would work better for Italian than for some other languages. Thanks for the recommendation of Il Provinciale; it looks interesting. Is it free to access if I create an account on the Rai website?
Thanks for the clarification. I see what you mean. Yes, Il Provinciale is one of the series that is available for free, once you sign in.
Boy oh boy, Ede. That's really kind of impressive! I had absolutely no idea about the book before I read this text and afterwards I still have no idea: D You can turn any piece of content into a statistical matter with a lot of data. But with every post I read, I get a better understanding about your program, so that's a nice side effect :D
:D :D