Bookwards: Rationale
In this post, I'm going to describe the rationale behind my recently published computer program for learning and maintaining vocabulary.
In a certain sense, this post is a continuation of my previous one, but it can be read independently. To be honest with you, I didn't really like the outcome of the last text and I hope this one turns out much better. Concretely, I hope it's readable and understandable for most (if not all!) Journaly users reading it. I really hope you find it informative and I'd, as always, welcome your constructive feedback. If you don't have any, you could always say hi or paste a funny racoon GIF or Youtube video about cats. There are never enough of them.
Please fasten your seat belts and get ready for an amazing technical roundtrip.
A computer program for improving vocabulary
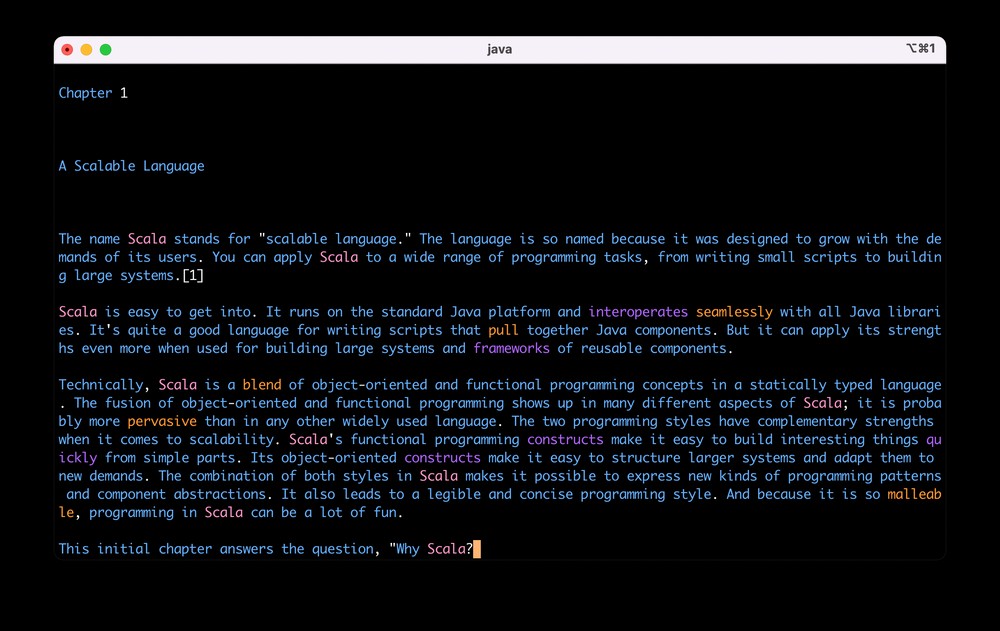
Similar to existing products like LingQ, LWT, FLTR or Readlang, the computer program I've written should help its users to improve their vocabulary. In contrast to the aforementioned existing products, mine really is a very minimal and simple product, which admittedly still has a couple of rough edges. Nevertheless, I hope it's usable in its current form. At least I certainly use it regularly with all my foreign and native languages. It looks like this:
In case you're by now curious about it, please take a look at https://hub.docker.com/r/edufuga/edwords. There you'll find instructions on how to run the program using Docker. I've not written the instructions on how to install Docker itself, but that's a very easy installation procedure under Linux and macOS. If you're using Windows, take a look at these instructions: https://docs.docker.com/desktop/windows/install/.
For the rest of this post, I'm going to describe the main technical details about the program and, like the title promises, the rationale in behind of it.
Note for techies: The source code of the program can be found here, in case you're curious. Please bear in mind that the current state of several of its parts is mostly a working prototype, which means that it works but the code is definitely not how I ideally would have liked to do it. I plan to improve on those parts in the near future, so that I'm finally content with it.
A bottom-up approach
The program has been written using a buttom-up approach. The most central part of the program is the "word-status-date" structure (what I call a "record"). Each record contains the user's self-assessed state of knowledge of a certain word in the form "word", "state of knowledge", "date of the self-assessment". An example could be: "cat, KNOWN, 2021-12-17 19:19:19".
The main data structure of the program is thus the tuple (word, state, date). Everything else follows logically from this fact or was constructed with this in mind.
Once the program "knows" how to represent the state of knowledge of words in general, the next logical step is to split a given text document into sentences and words. For this, I've written two regular expressions that work well for the languages that I speak and learn. Currently languages like Chinese would not work well with the program, I suppose. Until now, the program has been tailored to my specific language needs and ideas, but the charm of writing your own program is that one can always improve on that :). One of my long-term goals is to develop a generally useful program.
Everything is a file
The information (word, state of knowledge, date of the self-assessment) is saved as files on the hard drive. This is a quite strange idea for some computer users, I assume, but I personally find it absolutely charming. This is inspired by UNIX and Linux, where the idea "everything is a file" is quite central in these operating systems.
I wanted something as close to the operating system as possible. This excluded things like a SQL database for persisting (saving) the data. Furthermore, I wanted an easily navigable and "hackable" data structure, which means that the data itself should be usable without my program or other software. Everything one needs is a file browser and a text viewer or text editor: Your vocabulary is directly visible and inspectable without third-party tools. This provides a level of simplicity and transparency no database is able to achieve. But it has other issues. In the end, everything is a trade-off.
Not only the vocabulary knowledge is saved as files. Absolutely everything the program uses is a file: The book (or more generally, a text document) you read with it is a plain text file, the sentences and words in the text document are saved as files, the user-defined connections between concepts are saved as files, etc.
Atomicity of operations
Everything is saved atomically. This means that every new or reviewed word is a completely new file, which is directly written to the hard disk. File IO (input/output) is thus an essential part of the program. I didn't like the idea of writing a single file containing several words. Instead, I found the idea of "one word = one file" to be much better. That's what the wording "atomicity of operations" refers to. Every word file is an atomic part of the current state of knowledge of the vocabulary in a certain language.
Unicode support
Thanks to the Unicode support under Linux and macOS (and by now theoretically under Windows 10+ as well), it's possible to save files with (almost) arbitrary file names. This makes it viable to use the words themselves as file names. The result is a very simple representation of the vocabulary on the hard drive of the user.
Fast and direct information retrieval
The fact that the vocabulary is saved as files with every word as a file name (I call these "word files"), is important for yet another reason: fast word state retrieval.
What the heck are you talking about?
Well, I mean how the program obtains the information "how well does the user know this concrete word?". This is an almost trivial operation, from the point of view of the program: open the file with the word in its filename and read its contents. Every word file contains a single line, which lists the word, its state of knowledge according to the user's self-assessment, and the date of the assessment. Or stated differently: it contains the information on how well did the user know a certain word at a given moment in time. Because there are no indirections, the lookup is really fast. Furthermore, the program uses an internal caching mechanism to keep loaded words in memory in order to avoid redundancy. And even without that cache, modern operating systems do that nevertheless for files that are accessed often.
This is another reason for not wanting to have a database. A database is not only an opaque and possibly vendor-specific data structure, but it saves the vocabulary knowledge in a single place, a table. Imagine that I speak several languages and want to practise all of them (go figure); by using a database I'd be forced to save all of that in a single table, so the languages would not be physically separated at all. I personally find this a no-go. How I imagine things, my vocabulary knowledge should be neatly separated in different parts of my (computer's) memory.
So no databases.
Addendum for techies: Yes, I know there are other alternatives such as document-oriented databases, but I still find the documents (the text files) themselves to be the essential data abstraction.
Git
No, I'm not insulting you.
The last thing I want to mention in this by now too long post, is Git. One of the outcomes (or actually, one of the reasons in behind) of using files to save the vocabulary knowledge of someone using the program, is that it can be saved and versioned using Git, which provides a completely different paradigm to handling data than a database does. I could, for example, easily make my vocabulary knowledge in several languages openly accessible to anyone with an internet browser. In my eyes, this approach to open data is something appealing and worth striving for.
That's it for now
The post turned out to be a bit longer than I expected, but I hope it has been an interesting read. Please leave any comments you may have on it :)

Molto bene! Come va l'italiano?
I definitely need to try your program! The thing is that I'm currently using my phone for almost all my private stuff. 🙄
Hi Linda, thanks! Well, I need to get back to it again. After collecting 15,000 words with the program und using it to read Seta and the previous physics book, I stopped for a while.
What phone do you have? Android or iOS? In my case (Android), I have no problems using my program with it :), but that requires Termux + a Linux distribution in proot. If you're interesting in that, I could write the installation instructions in the near future. In fact, I mostly use my program on my smartphone.
Edit: According to my profile page, I've written "50 posts in 5 different languages" and "5555 inline comments". Now that satisfies my inner sense of symmetry :D. I won't ever write anything else on Journaly! 😆
That was a really pleasant text to read, Ede. Especially for people like me who have absolutely no idea about programming. I can imagine that many would be happy about such a program :D Hopefully there will be many people who can give you feedback!
Hi Lynn, thank you! Was ist denn deine eigene Meinung zum Programm an sich? Wäre es etwas für dich oder eher nicht?
Ich finde es klasse! Mir gefällt der Grundgedanke (sich in mehrerer Hinsicht eine Übersicht verschaffen zu können) und ich kann mir gut vorstellen, dass es Lernenden beim Lernprozess sehr helfen kann. Sei es durch die gewonnene Übersichtlichkeit oder die Motivation, immer mehr Worte in die "gelernt" Kategorie verschieben zu wollen. Vor allem für Leute, die eine ähnliche Affinität zu Zahlen, Daten und "Fakten" haben, wie du, ist das wahrscheinlich ein wahr gewordener Traum😁🎉. Für mich persönlich ist es wahrscheinlich nicht unbedingt etwas. Ich hatte mich mal an LingQ versucht und auch bei Netflix das "language learning" Add on installiert. Beide Male war ich dadurch aber eher genervt und abgelenkt. Ich glaube, mir ist sowas wie die Anzahl der Worte, oder deren Wissensstand darüber nicht wirklich wichtig. Und bei Netflix war ich dann echt von den Farben irritiert. Dein Programm ist definitiv eine geniale Idee, die sicher viele Leute begeistern kann. Es kommt halt, wie bei allem im Leben, auf die betreffende Person an😉. Das lernt man beim Unterrichten schnell. Was bei dem einen Lernenden funktioniert, klappt beim nächsten überhaupt nicht und umgekehrt. Deswegen heißt es aber noch lange nicht, dass die gewählte Methode falsch war, oder der Lernende unfähig. Du kennst sicher das Bild mit den Tieren, die alle einen Baum hochklettern sollen? So ist es tatsächlich. Ich werde deine Arbeit natürlich weiter gespannt verfolgen und gerne auch als Userin (Windows🙈) damit arbeiten, wenn es dir hilft😄. Wie immer viel zu viele Worte, um deine kurze Frage zu beantworten. Entschuldigung! 😆
Lynn, danke für deine ehrliche Antwort. Ich habe mir anhand deiner vorherigen Antworten schon so etwas gedacht. Die ganzen Farben können in der Tat etwas ablenkend bzw. nervig wirken. Bei mir hat es damit eine Weile gedauert, bis ich mich daran gewöhnt habe. Nun ist es so, dass ich beim Lesen eher das intuitive Verständnis davon habe und meistens nicht so richtig darauf achte. Idealerweise möchte ich auch eine Lösung finden, die auch für Menschen wie dich nützlich sein könnte. Sprich: Etwas, wo die Farben und die harten Zahlen eher im Hintergrund stehen (sie sind Teil des Mechanismus, nicht unbedingt des Produkts). Was würde dir denn helfen bzw. was würdest du dir an Funktionalitäten wünschen? Oder geht es so weit, dass du schon grundsätzlich sagst, Software fürs Sprachenlernen ist überhaupt nicht deins (warte, dann wärest du ja nicht hier xD). Meine aktuelle Idee ist, vor allem das Schreiben zu unterstützen (wie die letzten Posts vermuten lassen). Ich bin nämlich am überlegen (;)), was man damit machen könnte und wie das Programm und die damit erstellten Daten damit zusammenhängen. Etwas konkreter: Bis jetzt benutzt man mein Programm ganz bewusst, indem man Worte markiert bzw. eintippt. Mein Ziel wäre zu sehen, ob das auch unbewusst passieren kann, z. B. indem die Worte aus den Journaly-Posts extrahiert werden. In den letzten Tagen habe ich ein Mini-Programm geschrieben, was genau das macht: Es lädt die Posts herunter, extrahiert den Text, spaltet den Text in Sätze und Wörter auf, "berechnet" die Anzahl bzw. Häufigkeit jedes Worts in allen Posts und darauf aufbauend "entscheidet", wie gut ein:e User:in die Wörter seiner/ihrer Sprache kennt. Kurz gesagt: Das, was bis jetzt händisch passiert, geschieht automatisch: Die Kenntnis des Wortschatzes wird anhand des Inputs maschinell erstellt. Meine Vorstellung ist also, dass der Mechanismus meines Programms mit etwas Glück auch für Menschen sinnvoll sein könnte, die sich nicht gerne damit befassen :D. Wie immer viel zu viele Worte, um meine einfachen Gedanken niederzuschreiben. (Du musst dich für deine Ausführlichkeit definit nicht entschuldigen). Übrigens spricht es für sich selbst, dass du dir trotz alledem meine Texte konsequent durchgelesen hast!
Immer wieder gerne, Ede. Ich denke du weißt inzwischen, dass ich lieber ehrlich als höflich bin ;) Es ist aber beruhigend zu wissen, nicht die Einzige mit dieser Erfahrung des "genervt und abgelenkt" seins zu sein. Vor allem, wenn selbst du dich daran gewöhnen musstest, fühl ich mich nicht ganz so schlecht :D Hahaha~ natürlich nutze ich Software :D Um weiter ehrlich zu bleiben: Ich bin im Laufe der Jahre ein großer Freund von Anki geworden. Seit ich begriffen habe, wie man die Karten sinnvoll gestalten kann, macht es für mich einen gewaltigen Unterschied. Aaaaber... wenn ich die Möglichkeit hätte, ein Programm nach meinen Vorlieben zu gestalten, würde ich es wahrscheinlich nochmal komplett anders angehen. Ich merke immer wieder, wie wichtig der Kontext von Worten ist. Für mich wäre es genial, wenn ich beim Lesen eines Textes auf ein Wort klicken könnte und für dieses dann andere (sinnvolle!!!) Beispielsätze angezeigt bekomme (idealerweise incl. Audio). Eine andere Funktion, die ich genial fände, wäre die wortwörtliche Übersetzung eines Satzes. Also nicht die korrekte, sondern wirklich die wortwörtliche. Sowas wie: I really like watching movies - Ich wirklich mag schauen Filme. Dadurch lernt man die Satzstruktur uvm. Sowas hätte mir beim Koreanisch lernen, vor allem am Anfang, unendlich geholfen. Mini-Programm... Aha!!! Aus dieser neuen Idee stammen also die "Wer ist der gesuchte Journaly-Autor" Posts!! (Die 2 ist übrigens meine Lieblingszahl... also Danke ;D) Die neue Idee gefällt mir auch wieder sehr gut. Ich würde es tatsächlich aber anders nutzen. Wenn ich zum Beispiel ganz frisch in eine Sprache starte, könnte ich mir dadurch eine eigene "most used words" Liste erstellen und wüsste, welche Worte für mich persönlich besonders relevant sein könnten. Wie in meiner vorherigen Erläuterung schon gesagt: Ich persönlich lege einfach keinen Wert auf Zahlen in Bezug auf meinen Wortschatz. Es gibt irgendwo da draußen eine Geschichte, die ich mal aufgeschnappt habe, die das für mich gut verdeutlicht: Ein Japaner hat seit seiner Schulzeit jeden Tag ein paar neue Worte auf Englisch gelernt. Als er dann alt war und endlich einen Amerikaner traf, konnte er leider trotzdem nicht mit diesem sprechen, denn er hatte nie gelernt, wie man die Worte benutzt. Tja... und nun ist es doch wieder ein halber Roman geworden. Ich glaube, wir zwei IN_Ps müssen damit klar kommen, ausschließlich online Quasselstrippen (neues Wort für dich?) zu sein ;D
Ich kann mich auf diese tollen Antworten schnell gewöhnen, Lynn :). Ja, das weiß ich, deswegen finde ich gerade dein Feedback sehr hilfreich, wie ich dir in der Vergangenheit schon mal gesagt habe. So, ich mag Anki einfach nicht, denn es ist zu statisch. Du sagst selbst, du möchtest mehr Dynamismus darin haben (= andere Sätze zu einem gewählten Wort (dynamisch) ermitteln und anzeigen). Du sagst, es fehlt dir an Kontext. Das ist ja genau der Punkt, den ich mit meinem Program zu lösen versuche. Dein Beispiel mit dem Japaner finde ich hier aber unpassend, Lynn, denn mein Programm und meine Art, Wörter zu lernen, geschieht niemals losgelöst vom Kontext. Es sind ja die Sätze, welche die grundlegenden Begriffe und der Ausgangspunkt vom Rest bilden. Ein Wort ergibt sich immer als "zu einem bestimmten Satz gehörend", und diese Verbindung wird ja auch gespeichert. Alle Sätze mit dem Wort "Haus", zum Beispiel, werden in einem Textdokument "Haus.txt" gespeichert. Diese Datei wird dann beim Erfragen bzw. Üben des Wortschatzs verwendet, um gerade die Sätze mit diesem Wort anzuzeigen. Guck dir dazu vielleicht noch einmal das Video https://asciinema.org/a/ITnmr0TBJ4pMqs9RaxFcEO820 oder https://asciinema.org/a/c21OZ7RaPPqaXhSp6GTP2kdyS an. Dort siehst du, wie es ist, wenn ich das Wort als bekannt markiere oder so, aber wenn ich stattdessen auf die Leertaste drücke, werden andere Sätze mit diesem Wort angezeigt (insofern vorhanden). Das ist genau das, was du gesagt hast, denke ich. Nur passiert das (noch) nicht beim Lesen eines Buchs, sondern beim Üben des Wortschatzs in einem Buch. Ich kann mich aber problemlos vorstellen, dass es beim Lesen und/oder beim Schreiben sehr hilfreich sein könnte, diese Funktionalität anzubieten. Mit anderen Worten: Deine Idee ist etwas dynamischer Natur und passt genau zur Philosophie meines Softwareprojektes.
Edit: Ich habe nur für dich ;) dies aufgenommen: https://asciinema.org/a/1x93qkdlvY83DCKmQhQrG75UV
Die Sache mit den Audioaufnahmen ist auch etwas, was ich in letzter Zeit (wieder) überlege. Meine ursprüngliche Idee war (ist), selbst Worte und Sätze einzusprechen bzw. zu speichern (also dasgleiche Prinzip wie für die Wörter selbst, nur eben nicht geschrieben, sondern gesprochen). Alternativ könnte man sich überlegen, wie sinnvoll es wäre, auf vorhandenem Inhalt aus einem externen System zuzugreifen (es gibt Webportale, wo Muttersprachler Sachen aussprechen und so). Bis jetzt versuche ich aber mein Bestes, eine in sich abgeschlossene Umgebung zu entwickeln (deswegen gibt es zum Beispiel keine Online-Suche auf irgendwelchen Wörterbüchern oder Übersetzungen mit Google Translate oder so). Aber vielleicht könnte man darauf aufbauend bzw. als Ergänzung weiter in dieser Richtung gehen. Das ist mir aber alles noch nicht ganz klar.
Genau, das erwähnte Mini-Programm ist im Grunde ein Crawler + weitere Bestandteile, die zusammen aus jedem Post die Sätze und die darin enthaltenen Wörter extrahiert und speichert. Danach werden aus diesen Daten die Wortdateien erstellt, wie mein Programm sie braucht/versteht. Das Programm ist der erste Schritt in Richtung "Unterstützung beim Schreiben" oder, besser gesagt, "Kenntniserkennung der geschriebenen Wörter", im Grunde also ein Automatismus für Menschen wie dich, die glauben, Zahlen seien beim Wortschatzaufbau unnötig :P. Und ja, die Idee des Journaly Guessing Games ist daraus entstanden, genau.
Eine Frage, Lynn, zu deiner Anmerkung: Einerseits sagst du, dass du "einfach keinen Wert auf Zahlen in Bezug auf deinen Wortschatz legst", andererseits aber bist du "im Laufe der Jahre ein großer Freund von Anki geworden". Meine Frage ist: Soll das heißen, dass du im Anki z. B. dir nicht die Statistiken und Übersichten (Kreisdiagramme und so) angucken möchtest und auch nicht genau wissen möchtest, wie viele Wörter du kennst und wie viele nicht, usw., aber trotzdem gerne ein Program zum Lernen und Aufrechterhalten deines eigenen Wortschatzes (Wörter) im Kontext benutzt, richtig? Wenn ich damit recht habe, dann wäre mein Programm (vor allem der Questioner, also die Komponente, welche dir Sätze anzeigt und Wörter abfragt) für dich genau richtig, denke ich. Vielleicht sollte ich diesen Aspekt irgendwann nochmal genauer beschreiben, denn meine Analysen mit Zahlen+Fakten sind zwar für mich interessant und spaßig (vor allem, weil es kleine Programmierrätsel sind und so), für den Endverbraucher letztlich aber weniger interessant. Und was die Farben betrifft: Ja, sie sind vielleicht nervig, aber sie sind auch nicht immer unbedingt nötig. Sie sind Teil der Darstellung, nicht der Funktionsweise des Questioners. (Bei LingQ gibt es sowas nicht, es ist alles integriert in einem einzelnen Produkt, bei mir sind es eher mehrere kleine Tools, die nach Bedarf anders zusammengesetzt werden können). Entschuldige die langen Antworten, ich höre jetzt auf damit!
😲 Uff... That's a lot! Ede, I'd love to answer to all of this, but unfortunately, I'm extremely busy today and won't be able to sit down and write back everything I would want to write. That's why I'm going to answer you at some point this weekend. Just wanted to let you know in advance. 😁👋
All right, Lynn. Yes, sorry, I've let it all out :D.
Du meine Güte... kann mir bitte jemand erklären, warum ich das gestern auf Englisch geschrieben habe???? Ich muss echt völlig übermüdet gewesen sein. Sorry, Ede! Zum Glück kannst du ja Englisch, sonst wäre diese Nachricht ja echt komplett überflüssig gewesen xD
Also dann - ran an die Arbeit!
Wo fang ich denn am besten an? Am besten wäre wohl hier: Das Beispiel mit dem Japaner war eigentlich gar nicht auf dein Programm an sich bezogen, Ede. Sorry, wenn das so rüber kam. Es sollte schlicht verdeutlichen, was ich versucht habe zum Thema "Ich und Zahlen" zu erklären. Vor allem, wegen der möglichen "MOTIVATION in Zusammenhang mit der Anzahl der Worte im Wortschatz". Ich weiß, dass es für viele eine geniale Sache ist, die ihre Motivation beflügelt - für mich ist es eher eine Abschreckung oder Einschüchterung, wenn ich mit Zahlen konfrontiert werde. (Nicht nur beim Thema Sprachen übrigens! (Aber von meinem Problem mit Zahlen, weißt du vielleicht noch aus dem Kommentarbereich einer deiner ersten Physik-Seminare). Das hat also an sich gar nichts mit deinem Programm zu tun, denn die übergreifende Idee deines Programms finde ich nach wie vor unfassbar gut! Meine Motivation das Programm zu nutzen, wäre dann aber Zahlen unabhängig. Ich hoffe so war es besser ausgedrückt. Kurzfassung: Es liegt nicht an dem Programm, sondern, an einer persönlichen Präferenz.
Das Thema Anki schließt sich dann ja gleich an. Am Anfang bin ich genau deiner Meinung gewesen. Ich mochte das stupide "Wort für Wort Vokabellernen" auch gar nicht. Und diese ewig angezeigten Nummern (wie viele Karten man am Tag noch zu lernen hat usw.) kotzen mich bis heute an! Dann hab ich allerdings gelernt, mir mit Anki personalisierte Karten (also mit eigens ausgewähltem Kontext) zu erstellen. Zum Beispiel Karten mit Bildern/Fotos, eignen Lückentexten oder Tonaufnahmen (von Dialogen usw.). Man kann damit wirklich kreativ arbeiten, was ziemlich meinem Wesen entspricht.
Zu deinem Programm: Wie oben schon gesagt, bin ich weiterhin ziemlich fest von dem Nutzen und der Funktionalität deines Programms überzeugt. Die Sache mit den Farben, würde sich wahrscheinlich auch bei mir irgendwann legen. Vor allem, wenn diese Funktion - Alle Sätze mit dem Wort "Haus", zum Beispiel, werden in einem Textdokument "Haus.txt" gespeichert. Diese Datei wird dann beim Erfragen bzw. Üben des Wortschatzs verwendet, um gerade die Sätze mit diesem Wort anzuzeigen. - in den Hauptteil übergeht. Das es diese Funktion schon in dem anderen Bereich gibt, ist mir tatsächlich beim Ansehen der Videos entgangen! Sollte sich das tatsächlich umbauen lassen, würde ich dein Programm ohne Zweifel als ein neues Haupttool einsetzen. Mit anderen Worten: Deine Idee ist etwas dynamischer Natur und passt genau zur Philosophie meines Softwareprojektes. <- Na das freut mich!
Ohhh... Das wäre eine höllische Aufgabe. Solltest du die Idee wirklich weiter verfolgen wollen, wäre es vielleicht sinnvoller doch auf externe Daten zuzugreifen. Vielleicht könnte man "einfach" (Ich hab keine Ahnung von Lizenzen usw.) die Audiodatei von Hörbüchern/Hörspielen oder so nutzen? Zum Beispiel das Buch von Dan Brown (aus deinem kleinen aber feinen Viedeo - Danke dafür nochmal :D) gibt's doch bestimmt schon irgendwie vertont. Alles alleine einzusprechen, würde ich eine Unmenge an Zeit kosten.
Die Idee finde ich auch schon wieder ziemlich cool. Wirklich beeindruckend, was man so alles entwickeln kann :D Ich wünschte, ich hätte nur ansatzweise eine Ahnung vom Programmieren... das würde mir sicherlich auch viel Arbeit ersparen, wenn ich für einige Dinge einfach ein Programm entwickeln könnte. Untertitel sind für mich zum Beispiel eine Qual. Die selbst zu schreiben ist furchtbar aber die automatisch von YT erstellten, sind ein Witz -.- Und die, die ich online finden konnte, haben mich auch alle nicht so überzeugt.
:D oder, besser gesagt, "Kenntniserkennung der geschriebenen Wörter", im Grunde also ein Automatismus für Menschen wie dich, die glauben, Zahlen seien beim Wortschatzaufbau unnötig :P Hahaha~ aber das glaube ich immer noch :P Zumindest seh ich den Nutzen daraus immer noch nicht so ganz. Aber wenn es wirklich mal den Schreibprozess unterstützen kann, wäre es natürlich fantastisch!
Meine Frage ist: Soll das heißen, dass du im Anki z. B. dir nicht die Statistiken und Übersichten (Kreisdiagramme und so) angucken möchtest und auch nicht genau wissen möchtest, wie viele Wörter du kennst und wie viele nicht, usw., aber trotzdem gerne ein Program zum Lernen und Aufrechterhalten deines eigenen Wortschatzes (Wörter) im Kontext benutzt, richtig? Meine Antwort: Es gibt Statistiken und Übersichten bei Anki??? Ö.Ö Das wäre mir tatsächlich komplett neu!
... "der Questioner" für dich genau richtig, denke ich. -> Da denkst du richtig! Ich halte es für wichtig, dass neue Wissen schnellstmöglich vom passiven in den aktiven Wortschatz überzuführen. Dinge wie: Quizze, Fragen beantworten, vorgesprochenes selbst zu wiederholen, eigene Sätze mit den neuen Worten zu bilden, usw. sind meiner Meinung nach essentiell, um dem Lernenden auch in einen wirklich "Sprechenden" zu verwandeln.
Und was die Farben betrifft: Ich denke, auch ich könnte mich an die Farben irgendwann gewöhnen. Ich bin immer gewillt, mehrere Chancen zu geben. Immerhin sind LingQ und Netflix ja auch nicht dein Programm. Vielleicht ist es dabei ja auch nochmal eine völlig andere Erfahrung.
Ich hoffe, ich hab auf alles geantwortet... sollte was fehlen: Du weißt wo du mich findest ;)
Lynn, diesmal bin ich derjenige, der sich die Zeit nehmen wird, um deine wundervollen Kommentare weiter zu kommentieren :D, denn ich bin dieses Wochenende doch etwas beschäftigt mit anderen Sachen. Nur eins vorab:
Ich habe, glaube ich, noch gar nicht so richtig erwähnt, dass der Questioner auch "Cloze tests" macht. Wenn man die Taste "h" (für "hidden" oder "hide") drückt, muss man nicht nur das geübte Wort als bekannt/unbekannt markieren, sondern zuerst das Wort selbst schreiben. Auch hierfür habe ich gerade ein kleines Video aufgenommen: https://asciinema.org/a/9AuAfyGmzGmDkVJwdUSQFsWzK. Ich denke, das ist eine Art "Quizz", die dir gefallen könnte. Wie du an der Aufnahme siehst, ist diese Funktion noch nicht richtig stabil/rund, aber das kann man ja immer noch verbessern :). Deine Beispiele mit "Sätze bilden" und "Vorgesprochenes wiederholen" finde ich sehr gute Ideen, übrigens. Ich werde mir deine Kommentare später/morgen nochmal durchlesen und (weitere) Gedanken darüber machen, aber ich möchte mich jetzt schon dafür bedanken!
Ok, jetzt versuche ich endlich, mir etwas Zeit zu nehmen für deine letzten Kommentare.
Nun, das Beispiel mit dem Japaner habe ich in der Tat etwas persönlich genommen. Das ist jetzt aber geklärt. Deinen Punkt mit der Abschreckung und Einschüchterung verstehe ich aber nur zu gut (natürlich aus deinen Kommentaren in meinen Physik- und Mathe-Texten). Es ist auch beruhigend und gut zu lesen, dass du die (wie du es nennst) "übergreifende Idee meines Programms" gut findest, denn das war mir doch nicht so klar. Als ich mir selbst Anki-Karten erstellt habe (vor Ewigkeiten), habe ich auch kontextbezogene Sachen daraus gemacht (Wörte mit Beispielssätze), war mir aber trotzdem auf lange Sicht nicht gut genug, vor allem, wenn man bedenkt, wie zeitraubend die Erstellung davon und die Übung damit ist (und wie ineffizient). Das ist natürlich nur meine ganz persönliche Erfahrung damit. Die Sache mit den "Sätzen mit dem Wort 'Haus'" ist meiner Meinung eine der Kernfunktionalitäten meines Software-Projektes. (Ich sollte es nicht mehr "Programm" nennen, denn dann denkt man, es sei nur eine einzelne Sache, was nicht so ist). Mir persönlich macht es richtig viel Spaß, so (un)bekannte Worte zu üben bzw. einzugeben, denn ich sehe immer ein Beispielsatz mit dem zu ratenden/überlegenden Wort, das Lernen/Üben geschieht also immer im Kontext. Der Questioner, wie ich ihn nenne, ist für mich also das kleine Tool, mit dem ich Wörter erfasse. Ich habe in den vergangenen Posts eben die genauen Zahlen genannt, um zu zeigen, dass ich es selbst ernst nehme. Auf Niederländisch z. B. habe ich um die 35.500 Wörter eingegeben/geübt, was einfach ziemlich krank (ich meine cool) ist xD. Mit Anki hatte ich ab 700 Karteikarten aufgehört. Mir gefällt grundsätzlich, dass es schnell und einfach ist, Wörter einzugeben bzw. zu markieren, denn das erspart jede Menge Arbeit. Auch der Gedanke, nur die Wörter aus einem ganz bestimmten Buch bzw. Textdokument zu üben, ist entscheidend: Man soll ja vor allem das lernen, was (der eigenen subjektiven Empfindung nach) relevant ist.
Wie du im letzten Video vielleicht gesehen hast, gibt es auch die Möglichkeit von "Cloze Tests", also von Sätzen mit einem _____ darin, um das fehlende Wort zu überlegen und zu schreiben (also raten). Mit der Taste "?" kann man einzelne Buchstaben anzeigen, wenn man nicht weiß (oder man nicht zu lange überlegen möchte), was für ein Wort es überhaupt sein könnte xD. Die Idee ist, genau wie du sagst, "das neue Wissen schnellstmöglichst vom passiven in den aktiven Wortschatz überzuführen". Genau deswegen gibt es auch die einzelnen Zustände GUESSED, COMPREHENDED und KNOWN, um eben zwischen passivem und aktivem Wissen zu unterscheiden. Für mich heißt "guessed" einfach "geraten", "comprehended" ist für "passiv bekannt" und "known" ist für "aktiv bekannt". Mit dem Questioner erfasse ich also nicht nur ganz neue Wörter (die dem Programm nicht bekannt sind), sondern wiederhole bzw. übe die "alten" (die, die ich in der Vergangenheit angelegt habe). Das geschieht dann auch nach Kategorie: Ich starte den Questioner mit der Angabe, welche Kategorie (z. B. GUESSED) ich üben möchte. Im Idealfall gibt es dann den Übergang von GUESSED -> COMPREHENDED oder GUESSED -> KNOWN. Das ist das "Überführen", das du selbst erwähnst.
Zu den Audio-Aufnahmen: Ich meinte auch nicht, ein ganzes Buch einzusprechen, Lynn :D. Das wäre einfach verrückt (selbst für mich). Ich habe ehrlich gesagt keine Ahnung, was ich damit meinte, denn die Vorstellung ist noch sehr grob bzw. vage. Wahrscheinlich meine ich nur, einzelne Wörter aufzunehmen. Ich weiß aber auch nicht warum :D. Manchmal habe ich solche Ideen, wo ich etwas an sich cool finde, aber noch nicht genau weiß, warum bzw. wohin damit.
Zu der Unterstützung beim Schreiben: Auch das ist eine aktuell nicht ganz fertig ausgearbeitete Idee, sondern vielmehr ein Vorhaben und ein persönlicher Wunsch. Gut, so abstrakt ist es nun auch wieder nicht: Wie du schon gelesen hast, habe ich sehr wohl einen Texteditor, der mir mithilfe einer Syntaxdatei die Wörter markiert, welche ich direkt eingebe (damit schreibe ich übrigens diese Kommentare :D). Das ist aber wieder das, was du nicht so magst (farbige Wörter, igitt). Nun, das ist schon mal eine Art, den Schreibprozess zu unterstützen (auf eine Art, die aber nur für einige Menschen motivierend wirkt, für andere aber eigentlich den Umkehreffekt hat, da gebe ich dir recht). Eine andere Art, den Schreibprozess zu unterstützen, könnte sein, die einmal geschriebenen Wörter automatisch zu speichern und später beim Schreiben vorzuschlagen (Autocomplete-Funktion oder so). Noch eine Idee ist, aus den geschriebenen Wörtern automatisch "Kenntnis-Dateien" zu erstellen (also die Dateien aus meinem Programm, mit der Information "Wort, Zustand und Datum", bspw. "Haus, bekannt, jetzt gerade"). Damit kann man (automatisch) das eigene Wortschatz direkt aus den geschriebenen Texten extrahieren (um damit später coole und hoffentlich auch praktische Sachen machen zu können :D). Eben aus dieser Idee habe ich meine letzten kleinen Programme geschrieben und auch die Journaly Guessing Games. Noch eine Idee wäre, dies in Journaly selbst zu integrieren; darüber werde ich hoffentlich bald mit Robin (noch einmal und detaillierter) zu sprechen kommen. Wenn du diesbezüglich Ideen hast, her damit!
So, jetzt hoffe ich, ich habe die wichtigsten Punkten angesprochen. Entschuldige, wenn es wieder zu lang und wahrscheinlich auch wiederholt geworden ist.
Und nun bin ich wieder dran :D Also los geht’s! Nichts zu danken! Ich teile meine Gedanken gerne, wenn sie die richtigen Leute erreichen. Und solange du in meinem geschriebenen Chaos nicht den Überblick verlierst, kann ich dich gerne weiter damit „belästigen“ :P Dir natürlich auch Danke, für dein Vertrauen und die Offenheit, mit mir über deine Ideen zu sprechen, Ede! Ich mag die Idee deines Programms (oder Projekts) wirklich sehr gerne, weil ich den Nutzen dahinter ganz klar sehen kann. Ich glaube, sonst hätte ich LingQ und Language Learning Netflix auch gar nicht erst probiert, wenn ich die Idee nicht klar als (Lern-)gewinnbringend eingeordnet hätte.
Für mich ist der Questioner (und auch die Cloze Test Möglichkeit) allerdings wirklich das Highlight. Einfach unglaublich, dass ich den davor gar nicht wahrgenommen habe. Ich würde sogar fast behaupten, dass du damit eine Marktlücke schließen könntest. Wir machen solche Abfragen mit unseren Schüler:innen jedenfalls immer, wenn wir wissen wollen, ob sie die Inhalte wirklich verstanden haben. Und gleichzeitig machen (die meisten) Quizze und Rätsel auch noch Spaß und fördern daher die Motivation. Die Idee mit dem ersten Buchstaben, ist auch genau nach meinem Geschmack. Nicht zu viel und nicht zu wenig Hilfe! An deiner Stelle, würde ich diese Funktion wirklich mehr in den Vordergrund des Projekts rücken. Das ist eine perfekte Art, neue Informationen nochmal im Kontext zu üben. Besser geht es nicht! Zum Thema Sätze bilden, hätte ich eine Idee: Ich gebe Lernenden gerne die durcheinander gewürfelten Worte eines Satzes, die sie dann in die richtige Reihenfolge bringen müssen (wenn man es schwieriger machen möchte, kann man die Verben dabei in der Grundform stehen lassen). Vielleicht wäre das noch eine neue Idee. Dann fiel mir gerade noch die Variante „Fragen zum Text beantworten“ ein. Da wüsste ich aber nicht, wie man das mit deinem Programm umsetzen kann, wenn die Leser ihre selbst ausgewählten Texte damit Lesen/Lernen. Wir wissen ja immer, welche Texte wir im Unterricht mit den Kids erarbeiten und können dementsprechend inhaltliche Fragen vorbereiten. Eine andere tolle Übung ist, (die du in deinen Posts auch schon umgesetzt hast): Transkribieren. Das wäre allerdings eher ein Punkt zum Thema Audio. Und es muss ja auch nicht „nur“ ein Transkript dabei entstehen. Hier funktioniert auch das ausfüllen von Lückentexten oder Fragen zum Gehörten beantworten. Hahaha~ ja, die Anzahl ist cool (aber auch ein bisschen krank ;)) Ich kann aber total nachempfinden, dass du dabei sehr motiviert wurdest. Wenn etwas Spaß macht, dann macht man es ja auch noch lieber und so entsteht ein positiver Kreislauf :D
Naja, dann Ich kann deine Einstellung Anki gegenüber wirklich gut verstehen. Bei mir funktioniert Anki seit ein paar Wochen wieder besonders gut. Genauer: Seit ich die Kindl-App auf dem Handy habe. Ich lese derzeit ein Buch zum Thema Koreanisch lernen und kann da die Beispiele und Erläuterungen immer direkt zu Anki kopieren und anpassen. Lückentexte lassen sich so auch ziemlich schnell bauen, denn der Autor erklärt immer alles mithilfe eines Dialogs, denn ich dann modifizieren kann. Eine andere Sache, die ich an Anki sehr zu schätzen weiß: Ich habe es immer dabei und direkt griffbereit, sollte ich mal irgendwo Zeit totschlagen müssen. Aber wie gesagt: Jedem das seine! Ich kann deine Abneigung auch durchaus verstehen :)
Ganz kurze Antwort, Lynn: Ich gebe Lernenden gerne die durcheinander gewürfelten Worte eines Satzes, die sie dann in die richtige Reihenfolge bringen müssen -> Ich finde diese Idee einfach genial. Das werde ich sobald ich Zeit dafür habe sofort angehen. Fortsetzung folgt.
Hahahaha~ sei froh, dass du solche Gedanken/Ideen nur manchmal hast, Ede! Ich renne so ständig durch die Gegend. Ein weiterer Nachteil meines __FP Lebens. Neue Ideen und Gedankenexperimente sind für mich fast mit Sauerstoff gleichzusetzen. Wenn ich mal ein paar Stunden über nichts “Interessantes“ nachgedacht habe, fühle ich mich schrecklich. Du brauchst dich also keines Wegs für diese Art Gedanken/Ideen vor mir rechtfertigen. Es beruhigt mich aber tatsächlich zu wissen, dass du nicht vor hast ganze Bücher einzusprechen. Meine Stimmbänder tun alleine schon bei dem Gedanken weh :D Oh, interessant. Dann fällt sowas wie T9 wahrscheinlich in diese Autocomplete-Funktion? Hmm… Wenn dem so ist, weiß ich nicht, ob das wirklich sprachfördernd ist. Ich hab schon von vielen gehört, die vergessen haben, wie man Worte schreibt, weil ihr Handy ihnen immer die korrekte Form einsetzt. Und soweit ich weiß, entwickeln wir alle eine spezielle „Vorliebe“ für bestimmte Worte. T9 merkt sich das und präsentiert dann eher diese, als Alternativen. Aber darüber weiß ich wirklich zu wenig. Hab ich nur irgendwo aufgeschnappt und nie überprüft. Was ich damit eigentlich sagen wollte: Ich weiß nicht, ob ein Programm, wenn es einem die Denkarbeit abnimmt, wirklich Sprachfördernd wirkt. Die andere Funktion (Kenntnis-Dateien) klingt ebenfalls super interessant. Generell klingt alles an diesen ganzen Projekten und Ideen interessant :D Ich bin schon gespannt, wie sich das alles weiterentwickeln wird. Jetzt bin ich leider gerade nicht mehr munter genug, meine Gedanken/Ideen hier ordentlich zu formulieren. Das muss dann leider etwas warten. Ich hab aber tatsächlich eine, wie man hier auf Journaly ein allseits bekanntes „Problem“ lösen könnte. Ich versuche mal, dass ich hier morgen nach der Arbeit nochmal was dazu ordentlich formuliere xD Es ist wieder zu viel geworden, Sorry Ede! Und hetz dich bitte nicht mit der Antwort!
Kurze Zwischenmeldung: Ich spiele gerade mit der Idee nur ein bisschen rum (sie ist deutlich komplizierter und interessanter zu implementieren als ich zuerst gedacht habe; was ich habe, funktioniert in den meisten Fällen nicht richtig). Hier ein Beispiel ...
dennoch (?)
Shuffled sentence:
:D Häää? :D
Hahaha 😂Na muss es denn gleich ein so komplizierter Satz sein? Und wenn man es genau nimmt, könnte man auch die shuffle Version tatsächlich herausfinden. Dazu muss man wahrscheinlich aber auf einem sehr hohen Niveau sein oder den Text regelrecht verinnerlicht haben. Es feut mich jedenfalls sehr zu sehen, dass die Idee dir eine Inspiration war! Bin auf die nächsten Zwischenmeldungen gespannt 😁
Das war nur der Satz aus dem Buch, womit ich selbst den Questioner immer starte (= war gestern Abend zu faul, um ein anderes Buch dafür zu nehmen). Ja, mit dem zu hohen Sprachniveau hast du natürlich recht. Aber das ist ja nur ein Test bzw. Proof of Concept. Ich habe dabei ja auch alle Wörter untereinander mehrmals vertauscht. In der Praxis überlege ich, nur unbekannte (oder allgemeiner: Wörter derselben Kategorie) auszutauschen oder so. Also nur ein paar, nicht alle. Eigentlich überlege ich, mehrere Schwierigkeitsniveaus einzuführen, d. h. Sätze zu nehmen, die X unbekannte Wörter enthalten oder so (X ist eine einstellbare Zahl, der Benutzer würde also wählen, wie schwierig es werden sollte). Aber wie gesagt, bis jetzt habe ich nur mit der grundlegenden Umformung der Sätze gespielt. Ich habe gemerkt, dass das eine ziemlich große Änderung ist, die ich mir gut überlegen, richtig implementieren und ausführlich ausprobieren muss.
Hahaha. Jetzt habe ich es mit HP1 ausprobiert. Richtig witzige Sätze, die rauskommen.
nahe (?)
Shuffled sentence:
(sKopf ist natürlich nicht richtig, wie gesagt, es funktioniert noch nicht ganz; es fehlt die Information über Wortgrenzen/Wortpositionen).
Ein amüsantes Beispiel für einen falschen Satz ist:
(Jetzt rate mal, wie es richtig sein könnte xD, "Halslose" und "herklappte" sind witzige Fehler xD)
Noch ein Rätsel für dich, Lynn:
Warte, der ist auch gut:
Ich stelle mir gerade vor, wie Menschen einfach so sprechen xDD. Richtiges Yoda-Deutsch.
(Das könnte eine wunderbare Möglichkeit sein, um Muttersprachler:innen zeigen zu können, wie die eigene Sprache in den Ohren von Ausländern klingt. Lies mal den Satz vor! xD.
Hahahaha. Professor Geruch! Ich kann nicht mehr.
Noch mehr Yoda-Deutsch für Anfänger:
Das macht echt Spaß :D Hier mal mein erster Versuch… ist leider nicht komplett geworden. Ich hab aber echt keine Ahnung, wo ich „gehusteter“ einbauen soll. Und wenn ich HP nicht so gut kennen würde, wäre das mit dem fast Kopflosen Nick ein riesen Problem geworden xDD Der fast Kopflose (NICK??) hustete, freute sich über die verdutzten Gesichter der Gryffindors, um ihn (her?)rum, klappte seinen Kopf auf den Hals zurück und sagte: So – Übrig bleiben diese Teile: ( gehusteteter ! , )
Ja, der ursprüngliche Satz lautet so:
Das mit dem "gehusteteter" ist nur ein Fehler meines Programms. Ich habe aber eine Idee, wie ich ihn beheben, oder besser gesagt umgehen, kann.
Der war einfach: Dumbledore streckte die Hand aus und klopfte ihr sanft auf ihr(e?) Schultern.
Quirrell murmelte und klopfte suchend am Rahmen entlang: Dieser Stein ist der Schlüssel zum… Spiegel? xDDD Boah Ede… 2 Sätze zu vermischen, ist irgendwie unfair xD Immer wenn wörtliche Rede dabei ist, wird es gleich 5x so schwer!
Genau 🎉.
Bei dem letzten Satz, hab ich die Nomen durcheinander geworfen xDDD
Jaja, der Stein ist der Schlüssel zum Spiegel, Lynn. Ich glaube, du solltest das Buch noch einmal (diesmal aufmerksam, bitte) lesen!
Yes, ich habe den Fehler behoben/umgegangen :D. Zumindest haben die Sätze jetzt die gleiche Länge nach der Umformung, es wird also nichts mehr was verschluckt oder (wie der Fall war) wiederholt. Ich suche nach witzigen Beispielen...
Hahaha~ jaaaa! Ist doch logisch! Mit einem Stein, kann man einen Spiegel gut "öffnen" xDD Ne, quatsch. Ich wusste schon, dass es falsch ist aber wollte dir trotzdem mein Ergebnis zeigen :D Und das 1 Buch hab ich tatsächlich seit einer halben Ewigkeit nicht mehr gelesen...
Du solltest dich mal mit Japanisch oder Koreanisch auseinander setzen. Ich hab am Anfang Tränen gelacht. "Ich Apfel gerne esse." "Meine Mutter's Essen lecker ist." XD Die nutzen im Satz die SOV und nicht SVO Reihenfolge.
Hahaha, ja! Genial :D
Ich liebe dieses neue Feature. Guck mal was für großartige Schätze, ich meine Sätze, auftauchen:
Grandioser Zauberspruch: Türschloss!!
Sag mal wie kann man die Kommentare denn eigentlich formatieren??? Bei mir geht nicht mal mehr Absätze einfügen >__>
Mit Markdown: https://journaly.com/post/11547.
Die Absätze siehst du nicht beim Schreiben, aber sie sind da (du musst zweimal auf Enter drücken). Ansonsten mit
>mache ich die "Quotes".Ich glaube, ich schreibe bald einen eigenen Easter-Egg-BookReader mit den durcheinandergewürfelten Sätzen xD. Oder... Idee.
Test
Test
Okaaaay! Ich dachte, dass es in den Texten und Kommentaren unterschiedliche Formationen gibt :D Danke Ede!
neugivollgestopftig, Turbbehaupteten und übZombie finde ich noch viel besser xD
Wuuuhuu!!! Tolle Arbeit, Ede!
YES! Sehr gute Idee! So machen wir das auch immer. Du könntest es auch mit Lückentexten kombinieren. Also, dass in dem Satz sozusagen 3-4 Worte ausgeblendet werden und die Lösungsworte dann (durcheinander gewürfelt) angezeigt werden.
Muahahahaha. Lynn, guck mal: https://i.imgur.com/Ri9a7wX.png. Die Farben sind auf der rechten Seite noch nicht ganz passend, aber darauf kommt es jetzt nicht an (das Problem werde ich irgendwann angehen). Erstmal wollte ich den Text durcheinander haben und das ist jetzt erledigt. Ich hab's gerade im BookReader und im Questioner eingebunden :D. Beim Lesen gibt es jetzt den Schalter "b", um auf "Scrabble-Modus" umzustellen xDDD
Das Bild war etwas schwer zu "lesen" aber ich hab's dann doch geschafft. Sehr cool!!! :D Und der Name ist natürlich auch TOP! :D
Merkwürdigerweise kommte ich am Handy das Bild überhaupt nicht "lesen", aber mit dem Laptop funktioniert es problemlos. Nur die Bildbreite ist etwas zu groß, sorry. Na ja, im neuen Journaly-Post hast du einen ganzen Text mit Wirrwarr nach deinem Geschmack.
So ging es mir mit dem Bild auch. Am Laptop war's dann zum Glück ok. Und dein Wirrwarr-Text ist wahrscheinlich einer meiner liebsten Posts hier auf Journaly 😂👌 ich hab ihn vorhin sogar teilweise laut (und ganz ernst) gelesen und mich damit selbst zum lachen gebracht 🤣 zu schön!
Das habe ich gestern auch gemacht! Genau so wie du sagst. Ich musste es abbrechen. Mentale Notiz: So kann ich also Menschen für Physik begeistern :D
Mach die Notiz lieber nicht so groß... Ich weiß nicht, ob es bei Menschen im generellen Sinne klappt, oder nur bei Leuten wie mir, die über solche Dinge Tränen lachen können 😂
Schon klar :D. Ich glaube, bis jetzt begrenzt sich die Anzahl der Menschen, die den Text witzig finden, auf 2 oder 3 xD.